[충청뉴스 이성현 기자] 국내 연구진이 적은 데이터에서도 사람의 선호를 정확히 배우는 새로운 인공지능(AI) 학습 해법을 제시했다.
한국과학기술원(KAIST)은 전기및전자공학부 김준모 교수 연구팀이 인간의 선호를 효과적으로 반영하면서도 데이터 효율성과 학습 안정성을 크게 향상시킨 강화학습 프레임워크 ‘TVKD’(Teacher Value-based Knowledge Distillation)를 개발했다고 17일 밝혔다.
기존 인공지능 학습 방식은 'A가 B보다 낫다'는 식의 단순 비교 데이터를 대량으로 수집해 학습하는 구조였다. 이 방식은 많은 데이터가 필요하고 판단이 애매한 상황에서는 AI가 혼란에 빠지기 쉽다는 한계가 있었다.
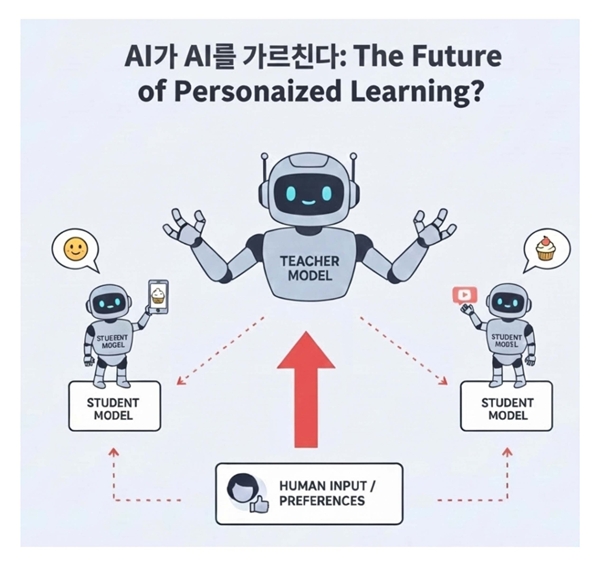
연구팀은 이러한 문제를 해결하기 위해 사람의 선호를 먼저 깊이 이해한 ‘교사(Teacher) 모델’이 그 핵심 정보만을 ‘학생(Student) 모델’에게 전달하는 방식을 제안했다.
이는 복잡한 내용을 정리해 가르치는 가정교사에 비유할 수 있으며 연구팀은 이를 ‘선호 증류’라고 명명했다.
이번 기술의 가장 큰 특징은 단순히 ‘좋다·나쁘다’를 흉내 내는 것이 아니라 각 상황이 얼마나 가치 있는지를 수치적으로 판단하는 ‘가치 함수’를 교사 모델이 학습한 뒤 이를 학생 모델에 전달하도록 설계했다는 점이다.
이를 통해 AI는 애매한 상황에서도 단편적인 비교가 아닌 ‘이 선택이 왜 더 나은지’를 종합적으로 판단하며 학습할 수 있다.
이번 기술의 핵심은 크게 두 가지다. 문맥 전체를 고려한 가치 판단을 학생 모델에 반영함으로써 단편적인 답변이 아닌 전체 흐름을 이해하는 학습이 가능해졌으며 선호 데이터의 신뢰도에 따라 학습 중요도를 조절하는 기법을 도입했다.
명확한 데이터는 학습에 크게 반영하고 모호하거나 잡음이 섞인 데이터는 영향력을 줄여 현실적인 환경에서도 AI가 안정적으로 학습할 수 있도록 했다.
그 결과 기존에 가장 성능이 좋다고 알려진 방법들보다 더 정확하고 안정적인 성능을 보였다.
특히 엠티-벤치(MT-Bench), 알파카-이밸(AlpacaEval) 등 주요 평가 지표에서 기존 최고 기술을 안정적으로 앞서는 성과를 기록했다.
김준모 교수는 “현실에서는 사람의 선호 데이터가 항상 충분하거나 완벽하지 않다”며 “이번 기술은 그런 제약 속에서도 AI가 일관되게 학습할 수 있게 해, 다양한 분야에서 실용성이 매우 높을 것”이라고 설명했다.
